全网整合营销服务商
电脑端+手机端+微信端=数据同步管理
免费咨询热线:17710347978

电脑端+手机端+微信端=数据同步管理
免费咨询热线:17710347978
各位站长朋友是否有遇到过网站被镜像的经历?你们是如何处理网站被镜像的呢?网站被镜像的危害是什么?网站被镜像了怎么办?危网站被镜像的处理方法又是什么呢?今天深山就来分享一下我的这个经历,提供给新手朋友们参考:

如何查看自己的网站是否被镜像了,分享两个简单的方法。
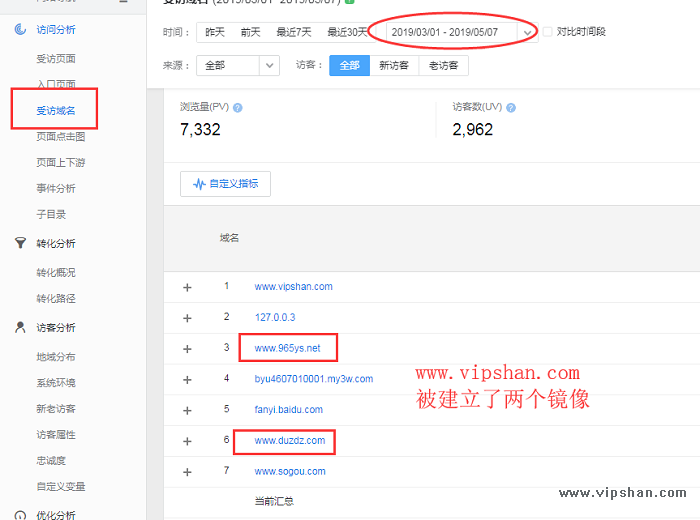
1.如果你网站安装了百度统计代码,则通过百度统计(tongji.baidu.com)中的受访域名查看,一般除了你自己的域名,其他的域名你都可以点进去看一看,这种方法的原理是什么呢?因为网站装了统计代码,而镜像的网站也有这段统计代码,统计的数据就从我这里看。
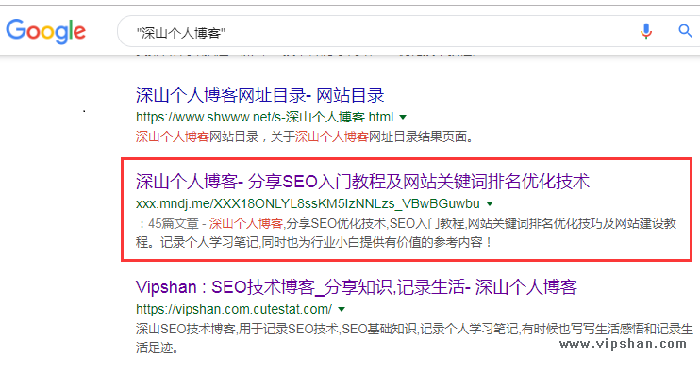
2.通过谷歌搜索自己网站的一些特殊词,因为搜索量太大、太寻常的词可能就搜不到那些镜像网站。为什么要用谷歌?因为百度一般不会收录这些网站,如何访问谷歌参考《如何访问谷歌?谷歌访问助手最新安装方法》。
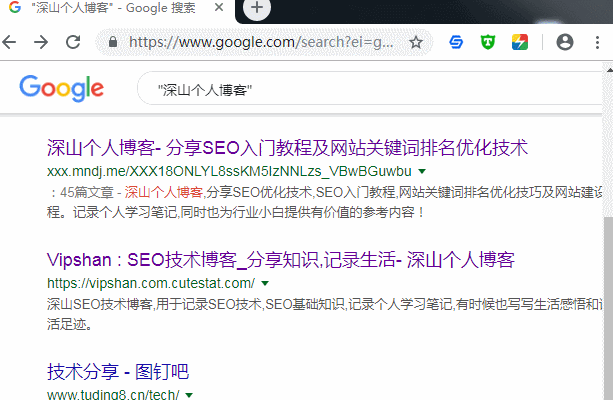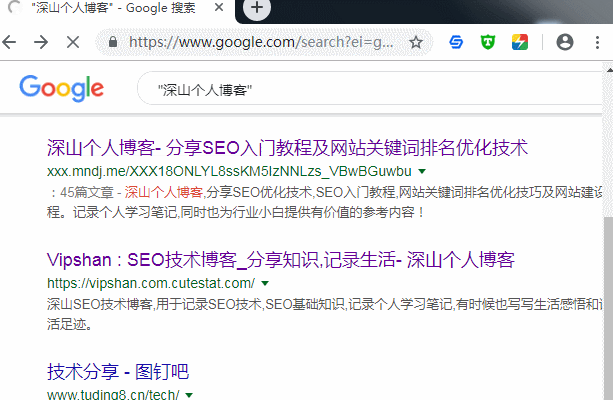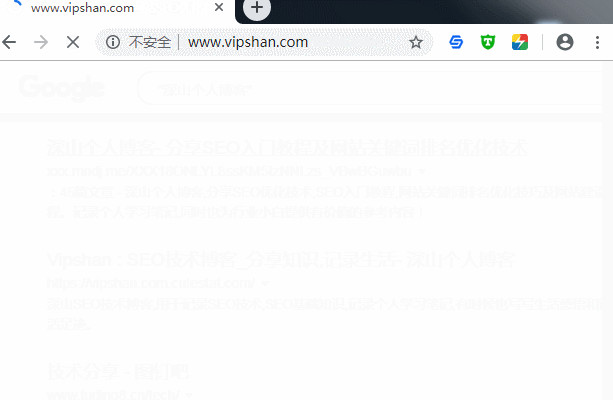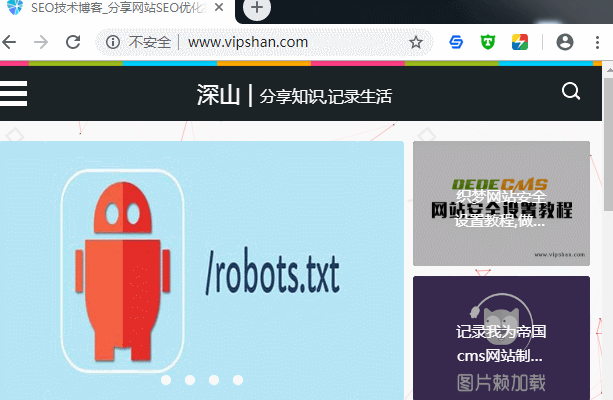
例如搜"深山个人博客"和"深山seo技术博客"这两个词,分别如下图,我们还可以利用其它的指令搜索,如下两图。
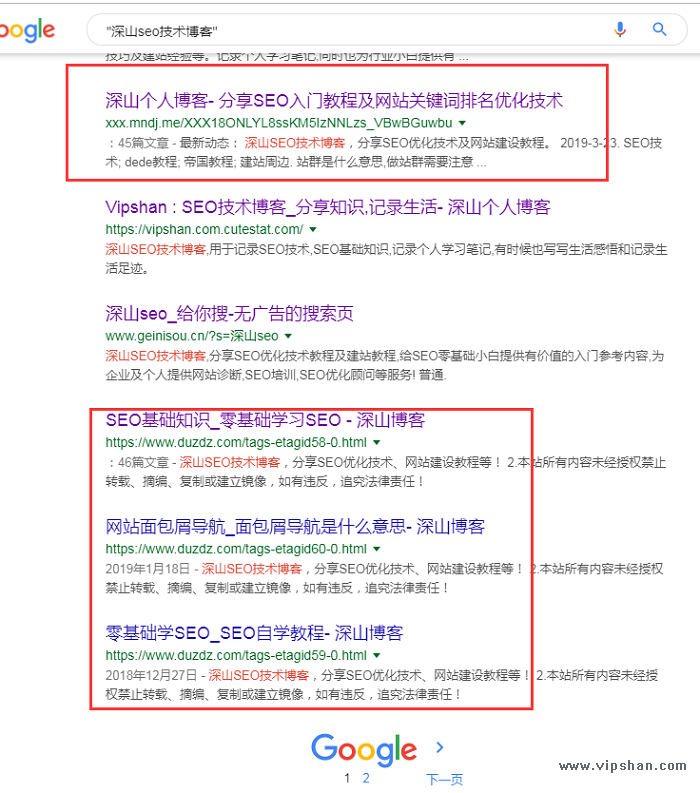
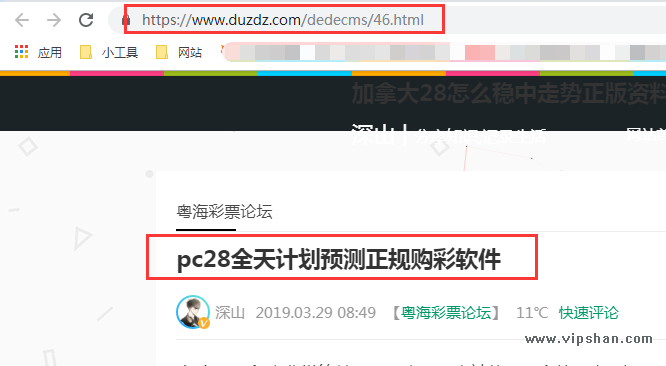
1.被非法网站镜像:就我上面截图的这两个站,一个是博彩站一个是色情站,这是危害之一,他们利用我们的品牌词截流,也就是博彩站或者色情站镜像我们的网站,然后别人搜索我们的品牌词(如深山seo博客)时有可能看到镜像的网站,从而获得流量。
2.新网站被镜像:如果你是个新站,你网站被镜像了,就会出现两个或者多个网站内容一模一样的,可能搜索引擎就认为你不是原版网站,认为镜像的那个才是,因此把排名和流量都给了镜像网站,你沦为了垃圾站。
3.老网站被镜像:如果你是老网站,上面说的,但是作为站长,眼睁睁看着别人镜像自己的网站,辛辛苦苦做的内容别人的镜像站还能实时更新,心里难免有些不爽。
1)新建一个ip.php的文件,添加以下代码,将ip.php传到你网站根目录,访问镜像网站:http://域名/ip.php,在我们的网站根目录上就会生成ip.txt文件并记录下镜像网站的真实IP。
$file = "ip.txt";//保存的文件名 $ip = $_SERVER['REMOTE_ADDR']; $handle =fopen($file,'a'); fwrite($handle,"IP Address:"); fwrite($handle,"$ip"); fwrite($handle,"\n"); fclose($handele); 或者使用 网站IIS日志查看获取镜像网站的真实ip,方法:随便建立一个页面 ,去镜像网站访问该页面,然后打开日志搜索建立的页面名称即可找到。
2)获得对方网站真实ip之后,Linux环境的网站可以通过.htaccess文件来将ip加入黑名单,代码如下
PS:
<IfModule mod_rewrite.c> RewriteEngine On #Block ip RewriteCond %{http:X-Forwarded-For}&%{REMOTE_ADDR} (154.215.102.102|154.215.102)[NC] RewriteRule (.*) -1)利用js代码禁止网站被镜像,js代码如下:
<script type="text/javascript"> rthost = window.location.host; if (rthost != "www.vipshan.com") { top.location.href = "http://www.vipshan.com"; } </script> 2)不过很多镜像网站都会将防止镜像的js代码过滤掉,因此我们需要给这段js代码加一点难度。打开chinaz站长工具http://tool.chinaz.com/js.aspx,对js代码进行混淆加密处理,处理后的代码如下:
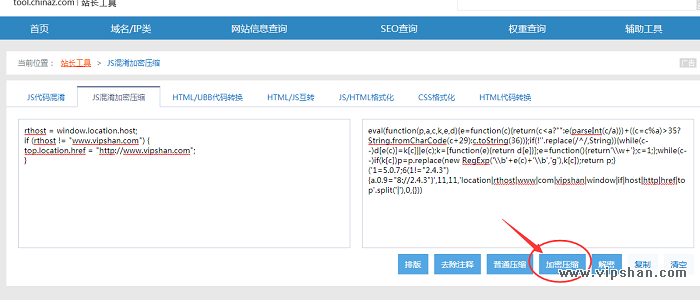
PS:你需要将上面没有混淆处理过的js代码中域名改为你自己的域名再进行混淆处理放到你的网站,不能直接用我混淆过的下面这段代码,不然就跳转到我网站来了
eval(function(p,a,c,k,e,d){e=function(c){return(c<a?"":e(parseInt(c/a)))+((c=c%a)>35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)d[e(c)]=k[c]||e(c);k=[function(e){return d[e]}];e=function(){return'\\w+'};c=1;};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p;}('<4 8="9/7">1=6.2.a;d(1!="0.5.3"){e.2.b="c://0.5.3"}</4>',15,15,'www|rthost|location|com|script|vipshan|window|javascript|type|text|host|href|http|if|top'.split('|'),0,{})) 这段js代码的原理是什么呢?当一个网站镜像我们网站的时候,会把这段js代码也镜像过去,这段js就会检测网站的域名是不是www.vipshan.com,如果不是就跳转回来(我也不懂程序,我理解的是这样的)。
最后奉上一张成功从镜像网站跳转到深山seo博客的动图(注意看地址栏地址变化):
www.duzdz.com这个站也是镜像我的深山个人博客这个站,不过它不是实时同步,而是将我博客的文件都缓存到他的服务器上,上面说到的通过js将镜像站点跳转回远站的方法就不奏效了,因为我的js文件等他都已经缓存在他服务器了,不过重中之重是,虽不是三四天吧,但它仍有更新,而是晚我的站几个小时,
我抱着试一试的心态将js跳转代码加到我博客的源代码中,我想的是:就算他原来的js文件都不变,但是我更新的文章它会更新出来,辣么我就把js跳转代码加到源代码中,我下回再更新文章的时候你同步我,就会将源代码中的js跳转代码也一同更新,果不其然,奉上一张动图(注意地址栏的变化):

如果是遇到那种下载你网站内容之后,以后都不会更新的,就没办法了,就只能通过向搜索引擎投诉快照或者联系站长走法律程序了。
内容载于深山个人博客
*请认真填写需求信息,我们会在24小时内与您取得联系。
